✏️ 한 줄 정리
많은 시스템 간에 데이터를 실시간으로 주고받게 해주는 고성능 메시지 브로커
Kafka란?
Apache Kafka는 대용량의 데이터를 빠르고 안정적으로 처리하기 위한 분산 메시지 큐 시스템
Kafka를 왜 사용할까?
웹 서비스에서 시스템이 많아지면 각 시스템 간 데이터 연동이 굉장히 복잡해지기 때문에 !
예를 들어, 주문이 발생하면 결제, 배송, 재고, 알림 등 연관된 모든 시스템이 "주문 발생" 이벤트를 알아야하는데,
이때 Kafka를 이용하면 한 번의 메시지 발행으로 여러 시스템이 동일한 이벤트를 받을 수 있다.
기본 개념
| 개념 | 설명 |
| Producer | 메시지를 Kafka로 보내는 주체 (ex. 주문 서버) |
| Consumer | Kafka에서 메시지를 구독해서 처리하는 주체 (ex. 배송 서버, 알림 서버 등) |
| Topic | 메시지가 분류되는 주제별 공간 (ex. "order-topic") |
| Broker | Kafka 서버 (여러 개 운영 가능) |
| Partition | Topic 내부의 물리적 분할 단위 -> 분산 처리, 병렬 처리 가능 |
| Offset | 메시지가 Kafka에 저장될 때 부여되는 고유 번호 (Consumer는 Offset을 기준으로 메시지를 읽음) |
웹 서비스에서 Kafka 사용하는 구조
[사용자 주문 요청]
↓
[주문 서버 (Producer)] → Kafka ("order-topic")에 주문 이벤트 발행
↓
[배송 시스템 (Consumer)] ← Kafka에서 메시지 수신 → 배송 시작
[알림 시스템 (Consumer)] ← Kafka에서 메시지 수신 → 알림 발송
[포인트 시스템 (Consumer)] ← Kafka에서 메시지 수신 → 포인트 적립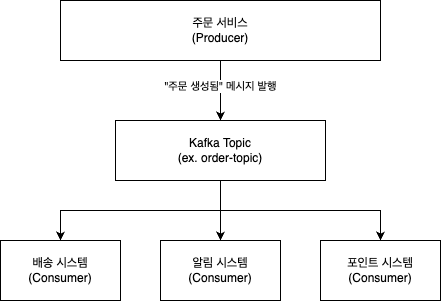
Kafka Partition 이란?
Kafka에서 Topic은 논리적인 메시지 단위인데,
이 Topic을 여러 개의 Partition(물리적 단위)으로 나누어 저장한다.
즉, 하나의 토픽은 여러 개의 파티션으로 구성되어있음 !
메시지는 특정 Partition에 저장되며, Partition 내에서는 순서가 유지되지만 전체 Topic 차원에서는 순서가 보장되지 않는다.
왜 Partition을 나눌까?
1. 성능 향상 (병렬 처리 가능)
여러 개의 Partition이 있으면, 여러 Consumer가 각 Partiion을 통해 동시에 처리할 수 있다.
2. 확장성 (분산 저장 가능)
Partition은 Kafka의 Broker들(서버들) 간에 분산 저장된다.
-> 데이터 양이 많아도 서버 여러 대에 나누어 저장 가능
3. 순서 보장
하나의 Partition 내에서는 메시지 순서가 보장된다.
(ex. Partition 0 에 들어간 메시지는 [msg1 -> msg2 -> msg3] 순서대로 처리됨)

메시지가 들어올 때 Kafka는 어떤 Partition에 저장할 지 결정 하는데,
- 기본은 Round-Robin 방식이다.
- 특정 Key가 있을 경우: Hash(Key) 기반으로 특정 Partition에만 저장
Partition과 Consumer 관계
Kafka에서 Consumer Group을 사용하면,
Partition과 Consumer는 다음과 같이 매칭된다.
Consumer Group A
├── Consumer 1 → Partition 0
├── Consumer 2 → Partition 1
├── Consumer 3 → Partition 2
- Partition 수 > Consumer 수 -> 일부 Consumer가 여러 Partition을 처리
- Partition 수 < Consumer 수 -> 일부 Consumer는 할 일이 없음 (비효율적)
그래서 실무에서는 "Partition 수 = Consumer 수"를 맞추는게 이상적임
'개발 > 알면 좋은' 카테고리의 다른 글
| 도커(Docker) (0) | 2025.03.28 |
|---|---|
| 클라우드 DB vs 물리 서버 DB (0) | 2025.03.28 |
| 데브옵스(DevOps) (0) | 2025.03.26 |
| 래디스(Redis) (0) | 2025.03.25 |